Overview¶
In this Notebook, you will learn some introductory concepts to automatic feature selection and hyperparameter tuning. We assume that you have already read over and completed the exercises in the Introduction to Supervised Learning Notebook for gesture recognition.
Resources¶
- Tuning Hyperparameters, Scikit-learn documentation
- Improving the Random Forest in Python, Will Koehrsen, Jan 2018
- Hyper-Parameter Tuning and Model Selection, Like a Movie Star, Caleb Neale, Jun 2019
- How to Tune Algorithm Parameters with Scikit-Learn, Jason Brownlee, Aug 2019
- Introduction to Machine Learning with Python, Andreas C. Müller & Sarah Guido, Oct 2016
About this notebook¶
This Notebook was designed and written by Professor Jon E. Froehlich at the University of Washington along with feedback from students. It is made available freely online as an open educational resource at the teaching website: https://makeabilitylab.github.io/physcomp/.
The website, Notebook code, and Arduino code are all open source using the MIT license.
Please file a GitHub Issue or Pull Request for changes/comments or email me directly.
Imports¶
# This cell includes the major classes used in our classification analyses
import matplotlib.pyplot as plt
import numpy as np
import scipy as sp
from scipy import signal
import random
import os
import math
import itertools
from IPython.display import display_html
# We wrote this gesturerec package for the class
# It provides some useful data structures for the accelerometer signal
# and running experiments so you can focus on writing classification code,
# evaluating your solutions, and iterating
import gesturerec.utility as grutils
import gesturerec.data as grdata
import gesturerec.vis as grvis
import gesturerec.signalproc as grsignalproc
from gesturerec.data import SensorData
from gesturerec.data import GestureSet
# Scikit-learn stuff
from sklearn import svm
from sklearn.preprocessing import StandardScaler, MinMaxScaler
from sklearn.pipeline import Pipeline
from sklearn.metrics import classification_report, accuracy_score, confusion_matrix
from sklearn.model_selection import cross_val_score, cross_validate, cross_val_predict, StratifiedKFold, GridSearchCV
from sklearn.model_selection import train_test_split
from sklearn.feature_selection import VarianceThreshold, SelectPercentile, SelectKBest, RFE
from sklearn.ensemble import RandomForestClassifier
from sklearn.tree import DecisionTreeClassifier
# Import Pandas: https://pandas.pydata.org/
import pandas as pd
# Import Seaborn: https://seaborn.pydata.org/
import seaborn as sns
Utility functions¶
def filter_correlated_features(df, filter_threshold = 0.95):
'''Filters out features with a Pearson correlation coefficient > filter_threshold
Based on: https://chrisalbon.com/machine_learning/feature_selection/drop_highly_correlated_features/
'''
# Take the abs value so both negative and positive correlations are mapped from 0 to 1
corr_matrix = df.corr().abs()
# Select upper triangle of correlation matrix
upper = corr_matrix.where(np.triu(np.ones(corr_matrix.shape), k=1).astype(np.bool))
# Find index of feature columns with correlation greater than filter_threshold
to_drop = [column for column in upper.columns if any(upper[column] > filter_threshold)]
print("Dropping", to_drop)
filtered_df = df.drop(columns=to_drop)
return filtered_df
def classify_df(input_df, clf, scaler, feature_selector, random_state = None):
# Drop the features like 'trial_num' 'gesturer' that are not actually input features
df = input_df.copy()
df_trial_indices = df.pop('trial_num')
df_gesturer = df.pop('gesturer')
df_gesture = df.pop('gesture') # ground truth labels
# Filter out highly correlated features
filtered_df = filter_correlated_features(df, 0.95)
print(f"Total features remaining: {len(filtered_df.columns)}")
# Setup an 80/20 split for training and testing stratified around gesture type
X = filtered_df # input features
y = df_gesture # ground truth labels
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, stratify=y, random_state=random_state)
# Train the model and compute a baseline classification score
clf.fit(X_train, y_train)
baseline_score = clf.score(X_test, y_test)
# Now scale data
scaler.fit(X_train)
X_train_scaled = scaler.transform(X_train)
X_test_scaled = scaler.transform(X_test)
# Compute scaled data score
clf.fit(X_train_scaled, y_train) # retrain model
scaled_data_score = clf.score(X_test_scaled, y_test)
print("Before scaling variance:")
display(pd.DataFrame(X_train.var(), columns=["Variance"]).T)
print("After scaling variance:")
scaled_df = pd.DataFrame(X_train_scaled, columns = filtered_df.columns)
display(pd.DataFrame(scaled_df.var(), columns=["Variance"]).T)
# Apply variance threshold
feature_selector.fit(X_train_scaled, y_train)
X_train_selected = feature_selector.transform(X_train_scaled)
X_test_selected = feature_selector.transform(X_test_scaled)
# Visualize filtered features
feature_selector_mask = feature_selector.get_support()
print(f"Feature elimination mask: {feature_selector_mask}") # Columns that are False were eliminated
print(f"Num of eliminated features: {len(np.where(feature_selector_mask == False)[0])}")
print(f"The eliminated features: {scaled_df.columns[~feature_selector_mask]}")
print(f"Feature indices to eliminate (in black below): {np.where(feature_selector_mask == False)}")
#fig = plt.figure(figsize=(15, 0.5)) # to change matshow figsize https://stackoverflow.com/a/43023727
#plt.matshow(~feature_selector_mask.reshape(1, -1), cmap='gray_r', fignum=fig.number)
plt.matshow(~feature_selector_mask.reshape(1, -1), cmap='gray_r')
plt.xlabel("Feature index")
plt.yticks(())
plt.show()
print(f"The final set of input features: {scaled_df.columns[feature_selector_mask]}")
# Compute final score (with filtered, scaled data)
clf.fit(X_train_selected, y_train) # retrain model
scaled_and_filtered_score = clf.score(X_test_selected, y_test)
print("---")
print(f"Baseline accuracy: {baseline_score:.3f}")
print(f"Scaled accuracy: {scaled_data_score:.3f}")
print(f"Scaled and filtered accuracy: {scaled_and_filtered_score:.3f}")
Load the data¶
These cells are the same as for the Shape Matching notebook. You should not need to edit them, only run them.
# Load the data
#root_gesture_log_path = './GestureLogsADXL335'
root_gesture_log_path = './GestureLogs'
print("Found the following gesture log sub-directories")
print(grutils.get_immediate_subdirectories(root_gesture_log_path))
gesture_log_paths = grutils.get_immediate_subdirectories(root_gesture_log_path)
map_gesture_sets = dict()
selected_gesture_set = None
for gesture_log_path in gesture_log_paths:
path_to_gesture_log = os.path.join(root_gesture_log_path, gesture_log_path)
print("Creating a GestureSet object for path '{}'".format(path_to_gesture_log))
gesture_set = GestureSet(path_to_gesture_log)
gesture_set.load()
map_gesture_sets[gesture_set.name] = gesture_set
selected_gesture_set = grdata.get_gesture_set_with_str(map_gesture_sets, "Jon")
if selected_gesture_set is None:
# if the selected gesture set is still None
selected_gesture_set = grdata.get_random_gesture_set(map_gesture_sets);
print("The selected gesture set:", selected_gesture_set)
The map_gesture_sets is a dict object and is our primary data structure: it maps gesture dir names to GestureSet objects. There's truly nothing special here. But we realize our data structures do require a learning ramp-up. Let's iterate through the GestureSets.
print(f"We have {len(map_gesture_sets)} gesture sets:")
for gesture_set_name, gesture_set in map_gesture_sets.items():
print(f" {gesture_set_name} with {len(gesture_set.get_all_trials())} trials")
# Feel free to change the selected_gesture_set. It's just a convenient variable
# to explore one gesture set at a time
print(f"The selected gesture set is: {selected_gesture_set.name}")
Preprocess the data¶
You may want to revisit how you preprocess your data. You can create one or more processed versions of each signal. For now, we'll just smooth the data using a sliding window.
def preprocess_signal(s):
'''Preprocesses the signal'''
# TODO: write your preprocessing code here. We'll do something very simple for now,
mean_filter_window_size = 10
processed_signal = np.convolve(s,
np.ones((mean_filter_window_size,))/mean_filter_window_size,
mode='valid')
return processed_signal
def preprocess_trial(trial):
'''Processess the given trial'''
trial.accel.x_p = preprocess_signal(trial.accel.x)
trial.accel.y_p = preprocess_signal(trial.accel.y)
trial.accel.z_p = preprocess_signal(trial.accel.z)
trial.accel.mag_p = preprocess_signal(trial.accel.mag)
for gesture_set in map_gesture_sets.values():
for gesture_name, trials in gesture_set.map_gestures_to_trials.items():
for trial in trials:
preprocess_trial(trial)
Feature extraction¶
This code is largely the same as as the Introduction to Supervised Learning Notebook but adds in a include_dummy_data variable. If True, we inject "dummy" variables into the feature set to demonstrate and evaluate the feature selection algorithms.
def extract_features_from_gesture_sets(gesture_sets, include_custom_gesture=True, include_dummy_data=False):
'''
Extracts features for all provided gesture sets.
Parameters:
gesture_sets: collection of GestureSet objects
include_custom_gesture: if True, includes the custom gesture. Otherwise, not.
include_dummy_data: if True, includes dummy features (for illustrative purposes)
'''
list_of_feature_vectors = []
column_headers = []
for gesture_set in gesture_sets:
(feature_vectors, cols) = extract_features_from_gesture_set(gesture_set, include_custom_gesture)
list_of_feature_vectors += feature_vectors
column_headers = cols
return (list_of_feature_vectors, column_headers)
def extract_features_from_gesture_set(gesture_set, include_custom_gesture=True, include_dummy_data=False):
'''
Extracts features from the gesture set
'''
list_of_feature_vectors = []
column_headers = None
gesture_names = None
if include_custom_gesture:
gesture_names = gesture_set.get_gesture_names_sorted()
else:
gesture_names = gesture_set.GESTURE_NAMES_WITHOUT_CUSTOM
for gesture_name in gesture_names:
gesture_trials = gesture_set.map_gestures_to_trials[gesture_name]
#print(gesture_name, gesture_trials)
for trial in gesture_trials:
features, feature_names = extract_features_from_trial(trial, include_dummy_data)
# add in bookkeeping like gesture name and trial num
# you shouldn't need to modify this part
features.append(gesture_set.get_base_path())
feature_names.append("gesturer")
features.append(gesture_name)
feature_names.append("gesture")
features.append(trial.trial_num)
feature_names.append("trial_num")
list_of_feature_vectors.append(features)
if column_headers is None:
column_headers = feature_names
return (list_of_feature_vectors, column_headers)
def extract_features_from_trial(trial, include_dummy_data=False):
'''Returns a tuple of two lists (a list of features, a list of feature names)'''
# Play around with features to extract and use in your model
# Brainstorm features, visualize ideas, try them, and iterate
# This is likely where you will spend most of your time :)
# This is the "feature engineering" component of working in ML
features = []
feature_names = []
# The features below may or may not be particularly good at gesture classification
# But they provide a reasonable start for you to begin classifying the gesture data
# Please add your own!
features.append(len(trial.accel.mag))
feature_names.append("signal_length (samples)")
# We are adding in a *REDUNDANT* input feature here again for illustrative
# purposes to show off our feature selection algorithms. The signal length
# in samples and in seconds are the same feature (just different representations)
# So they will be *perfectly* correlated
features.append(trial.accel.length_in_secs)
feature_names.append("signal_length (secs)")
features.append(np.max(trial.accel.mag)) # append feature
feature_names.append("mag.max()") # add in corresponding name
# Another potentially *REDUNDANT* feature depending on our preprocessing
features.append(np.max(trial.accel.mag_p)) # append feature
feature_names.append("mag_p.max()") # add in corresponding name
features.append(np.std(trial.accel.mag))
feature_names.append("std(mag.max())")
features.append(extract_feature_top_freq(trial.accel.mag, math.ceil(trial.accel.sampling_rate)))
feature_names.append("mag.top_freq")
features.append(extract_feature_num_peaks_freq_domain(
trial.accel.mag_p,math.ceil(trial.accel.sampling_rate),
min_amplitude_threshold=100))
feature_names.append("mag_p.fd.num_peaks")
# height is the height of the peaks and distance is the minimum horizontal distance
# (in samples) between peaks. Feel free to play with these thresholds
features.append(extract_feature_num_peaks_time_domain(trial.accel.mag_p, height=100, distance=5))
feature_names.append("mag_p.td.num_peaks")
#features.append(extract_feature_num_peaks_time_domain(trial.accel.y_p, height=100, distance=5))
#feature_names.append("y_p.td.num_peaks")
# If include_dummy_data is True, then we add in dummy variables to test our feature
# selection algorithms. Some features, like dummy_always15 (which is always the value 15)
# should be easy for our feature selection algorithms to detect. Others, like
# Guassian noise, maybe not so much...
if include_dummy_data:
features.append(15)
feature_names.append("dummy_always15")
features.append(999)
feature_names.append("dummy_always999")
val0or40 = 0
if random.random() > 0.5:
val0or40 = 40
features.append(val0or40)
feature_names.append("dummy_0or40_50%split")
val0or100 = 0
if random.random() > 0.9:
val0or100 = 100
features.append(val0or100)
feature_names.append("dummy_0or100_90%split")
features.append(random.randint(1,101))
feature_names.append("dummy_randint(1,101)")
features.append(random.gauss(100, 15))
feature_names.append("dummy_gauss(100, 15)")
return (features, feature_names)
def extract_feature_top_freq(s, sampling_rate, min_amplitude_threshold = 500):
(fft_freqs, fft_amplitudes) = grsignalproc.compute_fft(s, sampling_rate)
top_n_freq_with_amplitudes = grsignalproc.get_top_n_frequency_peaks(1, fft_freqs,
fft_amplitudes,
min_amplitude_threshold = min_amplitude_threshold)
if len(top_n_freq_with_amplitudes) <= 0:
return 0
return top_n_freq_with_amplitudes[0][0]
def extract_feature_num_peaks_freq_domain(s, sampling_rate, min_amplitude_threshold = 500):
(fft_freqs, fft_amplitudes) = grsignalproc.compute_fft(s, sampling_rate)
fft_peaks_indices, fft_peaks_props = sp.signal.find_peaks(fft_amplitudes, height = min_amplitude_threshold)
return len(fft_peaks_indices)
def extract_feature_num_peaks_time_domain(s, height=100, distance=5):
s_detrended = sp.signal.detrend(s)
# height is the height of the peaks and distance is the minimum horizontal distance
# (in samples) between peaks. Feel free to play with these thresholds
peak_indices, peak_properties = sp.signal.find_peaks(s_detrended, height=height, distance=distance)
return len(peak_indices)
Automatic feature selection¶
selected_gesture_set = grdata.get_gesture_set_with_str(map_gesture_sets, "Jon")
(list_of_feature_vectors, feature_names) = extract_features_from_gesture_set(selected_gesture_set)
sorted_gesture_names = sorted(selected_gesture_set.map_gestures_to_trials.keys())
# We'll convert the feature vector and feature names lists into Pandas tables
# which simply makes interacting with Scikit-learn easier
df = pd.DataFrame(list_of_feature_vectors, columns = feature_names)
Display a random part of the feature table
df.sample(8)
Remove parts of the DataFrame that are not actually input features and store them in vars for later.
df_trial_indices = df.pop('trial_num')
df_gesturer = df.pop('gesturer')
df_gesture = df.pop('gesture')
Display the input features.
print(f"{len(df.columns)} input features:")
print(df.columns)
Display input features alongside the ground truth labels.
grvis.display_tables_side_by_side(df, pd.DataFrame(df_gesture), n = 8,
df1_caption = f"{len(df.columns)} Input features",
df2_caption = "Ground truth labels")
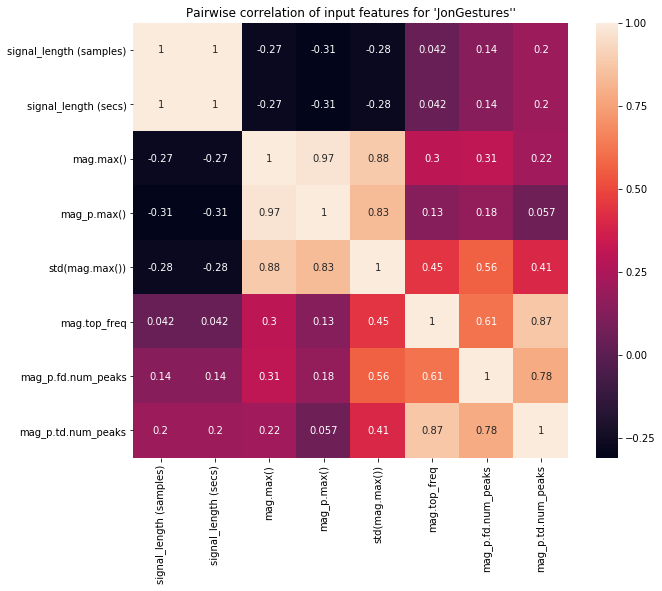
Pairwise correlation¶
As discussed in our last Notebook, we want features that have low (near zero) correlation with one another. If multiple features are highly correlated, then they will not improve our classification performance (and will also slow down training).
The function df.corr() computes a pairwise correlation of columns (by default, using a Pearson correlation, which measures the linear correlation between two variables).
For more on understanding the relationship between your input features and the Pearson correlation, read this article from Machine Learning Mastery.
# Compute and show the pairwise correlation table. Again, correlations vary between
# -1 to 1 where values closest to the extremes are more strongly correlated
pairwise_corr = df.corr()
display(pairwise_corr)
Plot the pairwise correlation¶
plt.figure(figsize=(10, 8))
sns.heatmap(pairwise_corr, square=True, annot=True)
plt.title(f"Pairwise correlation of input features for '{selected_gesture_set.name}''")
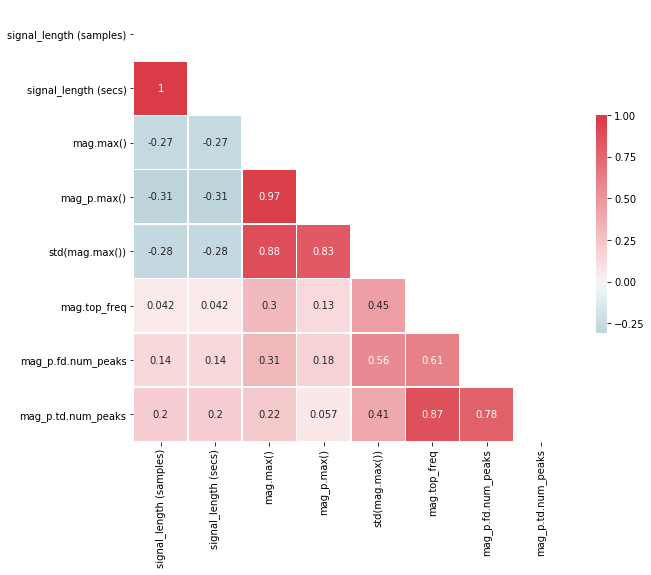
We can also plot a "prettier" version of the correlation matrix (that also takes advantage of its symmetry by only showing one side).
# Plot a "pretty" version of the correlation matrix
# Based on: https://seaborn.pydata.org/examples/many_pairwise_correlations.html
# Given that the correlation table is symmetrical, we remove one side
# Generate a mask for the upper triangle
mask = np.zeros_like(pairwise_corr, dtype=np.bool)
mask[np.triu_indices_from(mask)] = True
# Set up the matplotlib figure
f, ax = plt.subplots(figsize=(10, 8))
# Generate a custom diverging colormap
cmap = sns.diverging_palette(220, 10, as_cmap=True)
# Draw the heatmap with the mask and correct aspect ratio
sns.heatmap(pairwise_corr, mask=mask, cmap=cmap, vmax=1, center=0,
square=True, linewidths=.5, cbar_kws={"shrink": .5}, annot=True);
# Create correlation matrix
# Take the abs value so both negative and positive correlations are mapped from 0 to 1
corr_matrix = df.corr().abs()
# Select upper triangle of correlation matrix
upper = corr_matrix.where(np.triu(np.ones(corr_matrix.shape), k=1).astype(np.bool))
# Find index of feature columns with correlation greater than 0.95
to_drop = [column for column in upper.columns if any(upper[column] > 0.95)]
print(to_drop)
# Drop features
print(f"Dropping {len(to_drop)} features: {to_drop}")
filtered_df = df.drop(columns=to_drop)
print()
print("Remaining features:")
display(filtered_df.sample(5))
Pair plots¶
A slightly different version of the pairwise correlation grids is a pairplot, which graphs a pairwise scattplot between each variable in a cell and a univariate distribution along the diagonal. Pairplots combine our 2-dimensional explorations from before along with a pairwise correlation grid into a clean but highly information-dense visualization.
By default, just like the correlation grids above, the upper-right and lower-left (as split along the diagonal) are symmetrical. The diagonal shows a histrogram plot of the distribution of data for that variable.
For more information, see:
- Visualizing Data with Pair Plots, Towards Data Science, April 2018
- Section 1.7.3 of the Introduction to Machine Learning with Python book, Andreas C. Müller & Sarah Guido, Oct 2016
# Add the 'gesture' back into the DataFrame
pairplot_df = filtered_df.copy()
pairplot_df['gesture'] = df_gesture
# Create the pairplot (this might take a bit of time)
markers = grvis.plot_markers[:selected_gesture_set.get_num_gestures()]
sns.pairplot(pairplot_df, hue="gesture",
plot_kws = {'alpha': 0.8, 's': 80, 'edgecolor': 'k'},
markers = markers);

Visualizing effect of StandardScaler¶
Let's visualize the effects of StandardScaler as we will have to normalize our data for certain feature selection algorithms (e.g., VarianceThreshold) and classifiers (e.g., SVMs).
from sklearn.preprocessing import StandardScaler
#cols_to_norm = ['Age','Height']
#surveyData[cols_to_norm] = StandardScaler().fit_transform(surveyData[cols_to_norm])
cols_to_normalize = filtered_df.columns.values
normalized_df_standard_scaler = filtered_df.copy()
normalized_df_standard_scaler[cols_to_normalize] = StandardScaler().fit_transform(filtered_df[cols_to_normalize])
display(filtered_df.head(5))
display(normalized_df_standard_scaler.head(5))
display(normalized_df_standard_scaler.describe())
Now, let's visualize the normalized features. Compare the following pairplot to the one above. What do you see? To make the comparison easier, you could open this Notebook side-by-side in two tabs or copy one of the graphs as an image and open it in an image editor.
normalized_df_standard_scaler['gesture'] = df_gesture
sns.pairplot(normalized_df_standard_scaler, hue="gesture",
plot_kws = {'alpha': 0.8, 's': 80, 'edgecolor': 'k'},
markers = markers);

Visualizing effect of MinMaxScaler¶
from sklearn.preprocessing import MinMaxScaler
cols_to_normalize = filtered_df.columns.values
normalized_df_minmax_scaler = filtered_df.copy()
normalized_df_minmax_scaler[cols_to_normalize] = MinMaxScaler().fit_transform(filtered_df[cols_to_normalize])
display(filtered_df.head(5))
display(normalized_df_standard_scaler.head(5))
normalized_df_minmax_scaler['gesture'] = df_gesture
sns.pairplot(normalized_df_minmax_scaler, hue="gesture",
plot_kws = {'alpha': 0.8, 's': 80, 'edgecolor': 'k'},
markers = markers);

Variance threshold¶
Both standard deviation and variance measure the amount of variation in a set of values. Standard deviation is often more intuitive because it is expressed in the same units as the mean while variance is expressed in square units. More precisely, variance is the average of the squared differences from the mean (and standard deviation is just the square root of the variance).
$var = \frac{1}{N}\sum_{i=1}^n (x_i - \bar{x})$
$std = \sqrt{var}$
If a feature does not vary much between classes—in this case, gesture types—it is not going to be particularly informative to our classification model. For example, if an input feature is always 15 regardless of gesture, then the feature is meaningless. More formally, it's variance is 0, and we can remove it.
Scikit-learn has a built-in feature "selector" or "filter" for this called VarianceThreshold, which removes all features with a variance lower than a provided threshold. By default, this threshold is 0—that is, features that have the same value in all samples are removed.
Because variance is range dependent, normalization should be applied before using this technique (StackOverflow).
Let's try it!
Build new dataset¶
Let's start over with a new DataFrame with our input features and ground truth labels.
# Build our DataFrame of input features and ground truth labels
selected_gesture_set = grdata.get_gesture_set_with_str(map_gesture_sets, "Jon")
(feature_vectors, feature_names) = extract_features_from_gesture_set(selected_gesture_set)
df = pd.DataFrame(feature_vectors, columns = feature_names)
# Drop the features like 'trial_num' 'gesturer' that are not actually input features
df_trial_indices = df.pop('trial_num')
df_gesturer = df.pop('gesturer')
df_gesture = df.pop('gesture') # ground truth labels
# Filter out highly correlated features
filtered_df = filter_correlated_features(df, 0.95)
print(f"Total features remaining: {len(filtered_df.columns)}")
display(filtered_df.sample(8))
Explore feature variance¶
Let's look at the variance of the remaining features.
filtered_df.var()
Or perhaps it's easier to look at them in as HTML-formatted table.
display(pd.DataFrame(filtered_df.var(), columns=["Variance"]).T)
Normalize features¶
By default, VarianceThreshold filters out all features with a variance of 0—that is, they don't vary at all across samples. This is clearly not the case with our features. The signal_length (samples) variance, for example, is 19817.6. The least varying variable appears to be mag.top_freq—however, we have to be careful with drawing inferences here because each of these features have different ranges!
So, as noted above, we need to apply normalization first before applying the VarianceThreshold filter.
normalized_data = MinMaxScaler().fit_transform(filtered_df)
normalized_df = pd.DataFrame(normalized_data, columns = filtered_df.columns)
display(pd.DataFrame(normalized_df.var(), columns=["Variance"]).T)
Applying VarianceThreshold¶
Let's apply VarianceThreshold with a threshold of 0.03. Given the variance table above, only mag_p.td.num_peaks should be eliminated. And remember, typically, we would only do this on a training set. Here, we are applying it to our full dataset for illustrative purposes. Later, we'll show a full end-to-end example.
from sklearn.feature_selection import VarianceThreshold
feature_selector = VarianceThreshold(0.03)
filtered_data = feature_selector.fit_transform(normalized_df)
mask = feature_selector.get_support()
print(f"Feature elimination mask: {mask}") # Columns that are False were eliminated
print(f"Num of eliminated features: {len(np.where(mask == False)[0])}")
print(f"The eliminated features: {normalized_df.columns[~mask]}")
As expected, mag_p.td.num_peaks was eliminated. It's sometimes helpful to visualize the feature elimination mask, which we do below. Here, black means feature eliminated while white means feature included.
# visualize the mask: black means feature was eliminated
print(f"Feature indices to eliminate: {np.where(mask == False)}")
print(f"The eliminated features: {normalized_df.columns[~mask]}")
plt.matshow(~mask.reshape(1, -1), cmap='gray_r')
plt.xlabel("Feature index")
plt.yticks(());

We can also turn the remaining data back into a DataFrame (which simply makes it easier to visualize).
remaining_df = pd.DataFrame(filtered_data, columns = normalized_df.columns[mask])
display(remaining_df.head())
Full end-to-end classification example¶
Let's show a full end-to-end classification example with a VarianceThreshold of 0.03. This is purely for illustrative purposes. We are not recommending using a MinMaxScaler transform with a VarianceThreshold of 0.03 for actual gesture classification.
# Build our DataFrame of input features and ground truth labels
selected_gesture_set = grdata.get_gesture_set_with_str(map_gesture_sets, "Jon")
(feature_vectors, feature_names) = extract_features_from_gesture_set(selected_gesture_set)
df = pd.DataFrame(feature_vectors, columns = feature_names)
# Drop the features like 'trial_num' 'gesturer' that are not actually input features
df_trial_indices = df.pop('trial_num')
df_gesturer = df.pop('gesturer')
df_gesture = df.pop('gesture') # ground truth labels
# Filter out highly correlated features
filtered_df = filter_correlated_features(df, 0.95)
print(f"Total features remaining: {len(filtered_df.columns)}")
# Setup an 80/20 split for training and testing stratified around gesture type
X = filtered_df # input features
y = df_gesture # ground truth labels
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, stratify=y, random_state = 3)
# Create machine learning model
clf = svm.SVC(kernel='linear', C=1)
# Train the model and compute a baseline classification score
clf.fit(X_train, y_train)
baseline_score = clf.score(X_test, y_test)
# Now scale data
scaler = MinMaxScaler()
scaler.fit(X_train)
X_train_scaled = scaler.transform(X_train)
X_test_scaled = scaler.transform(X_test)
# Compute scaled data score
clf.fit(X_train_scaled, y_train) # retrain model
scaled_data_score = clf.score(X_test_scaled, y_test)
print("Before scaling variance:")
display(pd.DataFrame(X_train.var(), columns=["Variance"]).T)
print("After scaling variance:")
scaled_df = pd.DataFrame(X_train_scaled, columns = filtered_df.columns)
display(pd.DataFrame(scaled_df.var(), columns=["Variance"]).T)
# Apply variance threshold
feature_selector = VarianceThreshold(0.035)
feature_selector.fit(X_train_scaled, y_train)
X_train_selected = feature_selector.transform(X_train_scaled)
X_test_selected = feature_selector.transform(X_test_scaled)
# Visualize filtered features
feature_selector_mask = feature_selector.get_support()
print(f"Feature elimination mask: {feature_selector_mask}") # Columns that are False were eliminated
print(f"Num of eliminated features: {len(np.where(feature_selector_mask == False)[0])}")
print(f"The eliminated features: {scaled_df.columns[~feature_selector_mask]}")
print(f"Feature indices to eliminate (in black below): {np.where(feature_selector_mask == False)}")
plt.matshow(~feature_selector_mask.reshape(1, -1), cmap='gray_r')
plt.xlabel("Feature index")
plt.yticks(())
plt.show()
print(f"The final set of input features: {scaled_df.columns[feature_selector_mask]}")
# Compute final score (with filtered, scaled data)
clf.fit(X_train_selected, y_train) # retrain model
scaled_and_filtered_score = clf.score(X_test_selected, y_test)
print("---")
print(f"Baseline accuracy: {baseline_score:.3f}")
print(f"Scaled accuracy: {scaled_data_score:.3f}")
print(f"Scaled and filtered accuracy: {scaled_and_filtered_score:.3f}")

Adding dummy variables for experimentation¶
We can also add in some dummy features, some of which will be easier to detect such as the constant variables dummy_always15, which is always 15, and dummy_always999, which is always 999. And some of which will be harder for a VarianceThreshold approach to identify and filter, such as random gaussian distributions with a standard deviation of approximately 0.1 (feature name: dummy_normaldist_stddev0.1) and 3 (dummy_normaldist_stddev3).
We've also built a utility function called classify_df that does the exact same thing as the cell above (but just enables us to more cleanly run this code over and over, so we wrapped it in a function).
# Build our DataFrame of input features and ground truth labels
selected_gesture_set = grdata.get_gesture_set_with_str(map_gesture_sets, "Jon")
(feature_vectors, feature_names) = extract_features_from_gesture_set(selected_gesture_set)
df = pd.DataFrame(feature_vectors, columns = feature_names)
# Add in dummy variables
np.random.seed(20) # set the seed for consistency across executions
df['dummy_always15'] = np.full(len(df), 15)
df['dummy_always999'] = np.full(len(df), 999)
df['dummy_normaldist_stddev0.1'] = np.random.normal(0, 0.1, len(df))
df['dummy_normaldist_stddev3'] = np.random.normal(0, 3, len(df))
classify_df(df, svm.SVC(kernel='linear', C=1), MinMaxScaler(), VarianceThreshold(0.035), random_state = 3)

You'll note that while the VarianceThreshold approach was able to detect and eliminate dummy_always15 and dummy_always999, this was (likely) not the case for the "harder to detect" dummy features. (I say likely here because it depends on the random data).
Let's look at some more sophisticated approaches.
Univariate feature selection¶
A second feature selection approach uses univariate statistical tests. As Müller and Guido describe, "[with] univariate statistics, we compute whether there is a statistically significant relationship between each feature and the target. Then the features that are related with the highest confidence are selected. In the case of classification, this is also known as analysis of variance (ANOVA). A key property of these tests is that they are univariate, meaning that they only consider each feature individually. Consequently, a feature will be discarded if it is only informative when combined with another feature. Univariate tests are often very fast to compute, and don’t require building a model. On the other hand, they are completely independent of the model that you might want to apply after the feature selection" (Section 4.7.1).
Fortunately, once again, Scikit-learn has us covered with methods like SelectKBest, which removes all but the $k$ highest scoring features and SelectPercentile, which removes all but the highest scoring percentages of all features. We'll highlight just one technique below: SelectPercentile.
Note that these methods are supervised methods meaning that they need the target (ground truth) labels for fitting a model, which also means that to use these methods, we need to split our data into training and test sets and learn a feature selection model based only on the training set.
SelectPercentile¶
SelectPercentile selects the top N% performing features based on a univariate test (defaults to ANOVA).
Let's start by eliminating 20%of our input features (we have 10 input features after pairwise correlation elimination, so 20% will result in removing 2 features).
from sklearn.feature_selection import SelectPercentile
classify_df(df, svm.SVC(kernel='linear', C=1), MinMaxScaler(), SelectPercentile(percentile=80), random_state = 3)

How about removing 40% of features? This would correspond to our four dummy variables... can we detect them?
classify_df(df, svm.SVC(kernel='linear', C=1), MinMaxScaler(), SelectPercentile(percentile=60), random_state = 3)

SelectKBest¶
SelectKBest is the same as SelectPercentile but here you define the top $k$ features to select rather than a percentage. Let's try it with $k=4$.
from sklearn.feature_selection import SelectKBest
classify_df(df, svm.SVC(kernel='linear', C=1), MinMaxScaler(), SelectKBest(k=6), random_state = 3)

Recursive feature elimination (RFE)¶
Recursive feature elimination (RFE) selects features by recursively considering smaller and smaller sets of features (link). First, the estimator is trained on the initial set of features and the importance of each feature is obtained either through a coef_ attribute or through a feature_importances_ attribute. Then, the least important features are pruned from current set of features. That procedure is recursively repeated on the pruned set until the desired number of features to select is eventually reached.
RFE takes, as input, three key parameters:
- estimator: an estimator (or classifier) that provides information about feature importance either through a coef_ attribute or through a featureimportances attribute. This supervised model can be totally different than the one you use for classification.
- n_features_to_select: the number of features to keep. If None, defaults to half of the features.
- step: the number of features to step down by in each iteration. By default, is 1. If within (0.0, 1.0), then step corresponds to the percentage (rounded down) of features to remove at each iteration
See also Section 4.7.3 of Müller & Guido, Oct 2016.
from sklearn.feature_selection import RFE
from sklearn.tree import DecisionTreeClassifier
# n_features_to_select is the number of features to select. If None, selects top 50% performing features
feature_selector = RFE(DecisionTreeClassifier(random_state = 0), n_features_to_select=5)
classify_df(df, svm.SVC(kernel='linear', C=1), MinMaxScaler(), feature_selector, random_state = 3)

How about if we only keep three features:
feature_selector = RFE(DecisionTreeClassifier(random_state = 0), n_features_to_select=3)
classify_df(df, svm.SVC(kernel='linear', C=1), MinMaxScaler(), feature_selector, random_state = 3)

Using a RandomForestClassifier¶
Let's use a different model for RFE, how about a RandomForestClassifier, which trains a number of decision tree classifiers on various sub-samples of the dataset and uses averaging to improve the predictive accuracy and control over-fitting. This will be more computationally expensive but should lead to a better result.
feature_selector = RFE(RandomForestClassifier(n_estimators=100, random_state=42), n_features_to_select=3)
classify_df(df, svm.SVC(kernel='linear', C=1), MinMaxScaler(), feature_selector, random_state = 3)

How about if we select just one feature, which feature will be selected and what will the result be?
feature_selector = RFE(RandomForestClassifier(n_estimators=100, random_state=42), n_features_to_select=1)
classify_df(df, svm.SVC(kernel='linear', C=1), MinMaxScaler(), feature_selector, random_state = 3)

Hyperparameter Tuning¶
Hyperparameters—a term that I love (feels very Spaceballian)—are the parameters passed as arguments to a classification model. For example, with the k-Nearest Neighbor (kNN) algorithm, you can set the number of neighbors $k$ and the distance metric/similarity function; for a Support Vector Machine (SVM), you can set the C, kernel, and gamma hyperparameters, for Lasso, the alpha hyperparameter.
Hyperparameter tuning is typically the very last step in optimizing your full classification workflow.
Danger of overfitting parameters¶
To do hyperparameter tuning appropriately, we really need to split up our data into three parts.
- Parts 1 and 2 would be the typical cross-validation training and test sets, which we could also use for hyperparameter tuning
- Part 3 would be a final validation test set that we never touch until the very end and apply our trained and tuned model.

Why? Because we are learning these parameters using the test data.
We don't have enough data for this workflow, so we will continue to just split up our data into a cross-validation training and test set.
Manual hyperparameter grid search¶
As Müller and Guido explain, "Finding the values of the important parameters of a model (the ones that provide the best generalization performance) is a tricky task, but necessary for almost all models and datasets. Because it is such a common task, there are standard methods in Scikit-learn to help you with it. The most commonly used method is grid search, which basically means trying all possible combinations of the parameters of interest" (Section 5.2).
First, let's implement a manual grid search (based on Section 5.2.1 in the Müller and Guido book).
# Build our DataFrame of input features and ground truth labels
selected_gesture_set = grdata.get_gesture_set_with_str(map_gesture_sets, "Jon")
(feature_vectors, feature_names) = extract_features_from_gesture_set(selected_gesture_set)
df = pd.DataFrame(feature_vectors, columns = feature_names)
# Drop the features like 'trial_num' 'gesturer' that are not actually input features
df_trial_indices = df.pop('trial_num')
df_gesturer = df.pop('gesturer')
df_gesture = df.pop('gesture') # ground truth labels
# Setup an 80/20 split for training and testing stratified around gesture type
X = filtered_df # input features
y = df_gesture # ground truth labels
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, stratify=y, random_state = 3)
best_score = 0
for gamma in [0.001, 0.01, 0.1, 1, 10, 100]:
for C in [0.001, 0.01, 0.1, 1, 10, 100]:
# for each combination of parameters, train an SVC
clf = svm.SVC(gamma=gamma, C=C)
clf.fit(X_train, y_train)
# evaluate the SVC on the test set
score = clf.score(X_test, y_test)
print(f"Gamma={gamma} C={C} | Accuracy: {score}")
# if we got a better score, store the score and parameters
if score > best_score:
best_score = score
best_parameters = {'C': C, 'gamma': gamma}
print("-----")
print("Best score: {:.2f}".format(best_score))
print("Best parameters: {}".format(best_parameters))
GridSearchCV¶
Now, let's use the Scikit-learn version. The official Scikit-learn documentation states that GridSearchCV performs an "exhaustive search over specified parameter values for a classifier." We are going to use Stratified K-fold cross validation rather than a simple 80/20 test split.
param_grid = [
{'C': [1, 10, 100, 1000], 'kernel': ['linear']},
{'C': [1, 10, 100, 1000], 'gamma': [0.1, 0.01, 0.001, 0.0001], 'kernel': ['rbf']},
{'degree': [1, 10, 100, 1000], 'gamma': [0.1, 0.01, 0.001, 0.0001], 'kernel': ['poly']},
]
skf = StratifiedKFold(n_splits=5, shuffle=True, random_state=3)
clf = svm.SVC() # passing parameters here won't matter, since grid search does it for us
grid_search = GridSearchCV(clf, param_grid, cv=skf, return_train_score=True)
grid_search.fit(X, y)
print("Best parameters: {}".format(grid_search.best_params_))
print("Best cross-validation score: {:.2f}".format(grid_search.best_score_))
print("Best estimator:\n{}".format(grid_search.best_estimator_))
Display grid search results in a DataFrame¶
We can grab the entirety of the grid search results, which are stored as a dictionary in grid_search.cv_results_ and throw them into a DataFrame for easy viewing and manipulation.
Let's show the top 10 results sorted by mean_test_score then std_test_score.
grid_search_results_df = pd.DataFrame(grid_search.cv_results_)
sorted_grid_df = grid_search_results_df.sort_values(by=['mean_test_score', 'std_test_score'], ascending=False)
display(sorted_grid_df.head(n=10))
Let's print out the same table but just the columns of key interest for us at the moment.
cols_of_interest = ['params', 'mean_test_score', 'std_test_score', 'rank_test_score']
display(sorted_grid_df[cols_of_interest].head(n=10))
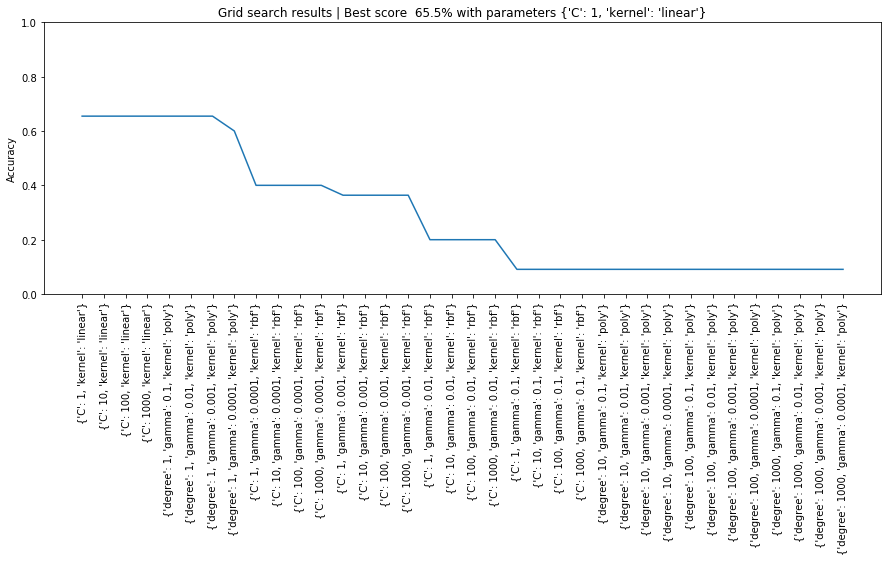
Line graph of grid search results¶
Let's plot a line graph of the grid search results sorted by mean_test_score.
# plot of grid search
x = np.arange(0, len(sorted_grid_df), 1)
plt.figure(figsize=(15, 5))
plt.plot(x, sorted_grid_df['mean_test_score'])
plt.xticks(x, sorted_grid_df['params'], rotation='vertical')
plt.ylabel("Accuracy")
plt.ylim(0, 1)
plt.title(f"Grid search results | Best score {grid_search.best_score_ * 100: 0.1f}% with parameters {grid_search.best_params_}")
plt.show()
Heatmap of grid search¶
We can also create other visualizations of the results, which help us understand the relationship between hyperparameters and performance
grid_search_results_df_kernel = grid_search_results_df[grid_search_results_df.param_kernel == 'rbf']
results_df_rbf = grid_search_results_df_kernel[['mean_test_score', 'param_C', 'param_gamma']]
#display(results_df_rbf)
pivot_rbf = pd.pivot_table(results_df_rbf, values='mean_test_score', columns='param_C', index='param_gamma')
grid_search_results_df_kernel = grid_search_results_df[grid_search_results_df.param_kernel == 'poly']
results_df_poly = grid_search_results_df_kernel[['mean_test_score', 'param_degree', 'param_gamma']]
#display(results_df_rbf)
pivot_poly = pd.pivot_table(results_df_poly, values='mean_test_score', columns='param_degree', index='param_gamma')
fig, axes = plt.subplots(1, 2, figsize=(20, 5))
sns.heatmap(pivot_rbf, ax=axes[0])
sns.heatmap(pivot_poly, ax=axes[1])
axes[0].set_title("RBF kernel grid search results")
axes[1].set_title("Poly kernel grid search results")
#plt.title(gesture_set.name)
#plt.show()
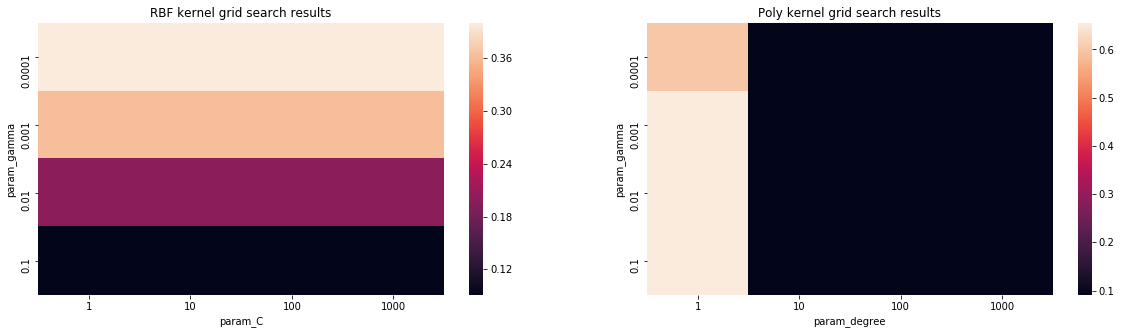
Running GridSearchCV with a pipeline object¶
Clearly, grid search is a really powerful experimental framework to allow us to evaluate the efficacy of different hyperparameters; however, we only tested a raw classifier above. Recall that we actually have a full pipeline of scaling data, feature selection, etc.
Running with scaling¶
# Setup pipeline object
pipeline = Pipeline([('scaler', StandardScaler()), ('estimator', svm.SVC())])
# Setup our hyperparameter ranges for the grid search.
C_range = np.logspace(-2, 10, 13) # old: [1, 10, 100, 1000, 5000, 10000]
gamma_range = np.logspace(-9, 3, 13) # old: [1000, 100, 10, 1, 0.1, 0.01, 0.001, 0.0001]
# The hierarchy in the pipeline can be reached using double underscore(‘__’)
param_grid = [
{'estimator__degree': [1, 2, 3, 4], 'estimator__gamma': gamma_range, 'estimator__kernel': ['poly']},
{'estimator__C': C_range, 'estimator__kernel': ['linear']},
{'estimator__C': C_range, 'estimator__gamma': gamma_range, 'estimator__kernel': ['rbf']},
]
skf = StratifiedKFold(n_splits=5, shuffle=True, random_state=3)
grid_search = GridSearchCV(pipeline, param_grid, cv=skf, return_train_score=True)
grid_search.fit(X, y)
print("Best parameters: {}".format(grid_search.best_params_))
print("Best cross-validation score: {:.2f}".format(grid_search.best_score_))
print("Best estimator:\n{}".format(grid_search.best_estimator_))
Let's dive into the results a bit more. First, show a table of the top 10 results, which helps us see the drop off in performance and which params were most effective.
grid_search_results_df = pd.DataFrame(grid_search.cv_results_)
sorted_grid_df = grid_search_results_df.sort_values(by=['mean_test_score', 'std_test_score'], ascending=False)
cols_of_interest = ['params', 'param_estimator__kernel', 'mean_test_score', 'std_test_score', 'rank_test_score']
display(sorted_grid_df[cols_of_interest].head(n=10))
And let's graph this data just as we did before:
# plot of grid search
x = np.arange(0, len(sorted_grid_df), 1)
plt.figure(figsize=(15, 5))
plt.plot(x, sorted_grid_df['mean_test_score'])
# Can't really change the x-ticks here. Too many params
# plt.xticks(x, sorted_grid_df['params'], rotation='vertical')
plt.ylabel("Accuracy")
plt.ylim(0, 1)
plt.title(f"Grid search results | Best score {grid_search.best_score_ * 100: 0.1f}% with parameters {grid_search.best_params_}")
plt.show()
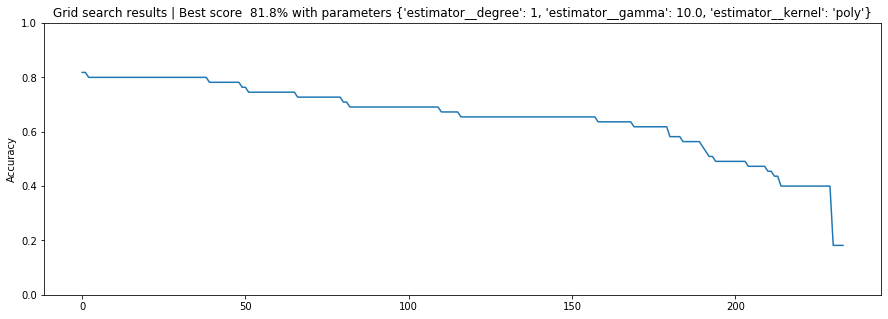
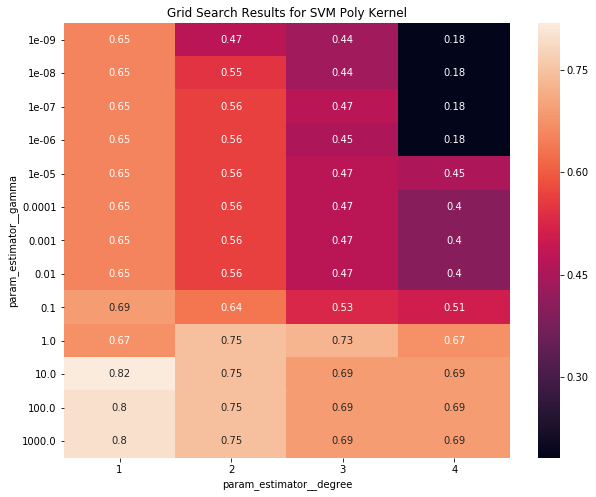
Poly and linear kernels seemed to perform best. Let's make a heatmap of the poly grid search
grid_search_results_df_kernel = grid_search_results_df[grid_search_results_df.param_estimator__kernel == 'poly']
results_df_poly = grid_search_results_df_kernel[['mean_test_score', 'param_estimator__degree', 'param_estimator__gamma']]
pivot_poly = pd.pivot_table(results_df_poly, values='mean_test_score',
columns='param_estimator__degree', index='param_estimator__gamma')
fig, ax = plt.subplots(1, 1, figsize=(10, 8))
sns.heatmap(pivot_poly, ax=ax, annot=True)
ax.set_title("Grid Search Results for SVM Poly Kernel")
Running with scaling and feature selection¶
Now, let's include some feature selectors in our pipeline as well.
scaler = StandardScaler() #RobustScaler()
feature_selector = SelectKBest(k=5)
pipeline = Pipeline([('scaler', scaler), ('selector', feature_selector), ('estimator', clf)])
# Setup our hyperparameter ranges for the grid search.
C_range = np.logspace(-2, 10, 13) # old: [1, 10, 100, 1000, 5000, 10000]
gamma_range = np.logspace(-9, 3, 13) # old: [1000, 100, 10, 1, 0.1, 0.01, 0.001, 0.0001]
# The hierarchy in the pipeline can be reached using double underscore(‘__’)
param_grid = [
{'selector__k': [4, 5], 'estimator__degree': [1, 2, 3], 'estimator__gamma': gamma_range, 'estimator__kernel': ['poly']},
{'estimator__C': C_range, 'estimator__kernel': ['linear']},
{'estimator__C': C_range, 'estimator__gamma': gamma_range, 'estimator__kernel': ['rbf']},
]
skf = StratifiedKFold(n_splits=5, shuffle=True, random_state=3)
clf = svm.SVC()
grid_search = GridSearchCV(pipeline, param_grid, cv=skf, return_train_score=True)
grid_search.fit(X, y)
print("Best parameters: {}".format(grid_search.best_params_))
print("Best cross-validation score: {:.2f}".format(grid_search.best_score_))
print("Best estimator:\n{}".format(grid_search.best_estimator_))
Jon's Sandbox/Notes¶
As usual, you can ignore anything in this section. :)
- Show what it's like when we combine everyone's data and plot it in pairplot
- Show how to use feature selector's in pipeline objects
- Show how to use feature selectors, hyper parameter tuning with cross-user models
- TODO: possibly: https://www.pyimagesearch.com/2016/08/15/how-to-tune-hyperparameters-with-python-and-scikit-learn/
How to add variance to Describe table¶
filtered_df_stats = normalized_df.describe()
filtered_df_stats.loc['variance'] = filtered_df_stats.loc['std']**2
print("Before normalization:")
display(filtered_df_stats)
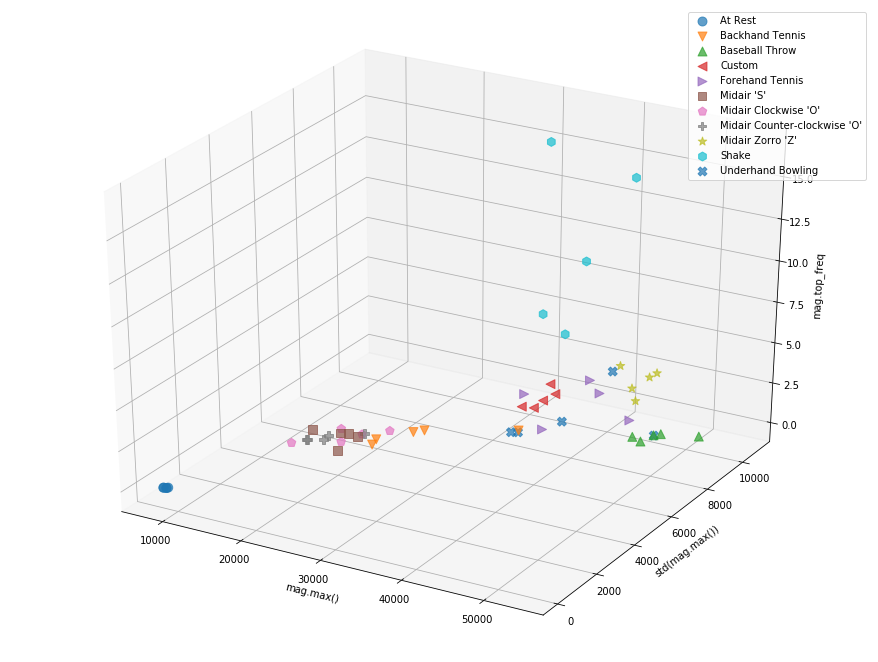
Plotting in 3D¶
#TODO make this interactive
from mpl_toolkits.mplot3d import Axes3D
fig = plt.figure(figsize=(12, 9))
ax = Axes3D(fig)
df_plot = filtered_df.copy()
df_plot['gesture'] = df_gesture
i = 0
x_feature_name = 'mag.max()'
y_feature_name = 'std(mag.max())'
z_feature_name = 'mag.top_freq'
x_col_idx = df.columns.get_loc(x_feature_name)
y_col_idx = df.columns.get_loc(y_feature_name)
z_col_idx = df.columns.get_loc(z_feature_name)
for grp_name, grp_idx in df_plot.groupby('gesture').groups.items():
x = df.iloc[grp_idx,x_col_idx]
y = df.iloc[grp_idx,y_col_idx]
z = df.iloc[grp_idx,z_col_idx]
ax.scatter(x, y, z, label=grp_name, marker = markers[i], s=80, alpha=0.7) # this way you can control color/marker/size of each group freely
i = i + 1
ax.legend()
ax.set_xlabel(df.columns[x_col_idx])
ax.set_ylabel(df.columns[y_col_idx])
ax.set_zlabel(df.columns[z_col_idx])